
News
Tuesday, September 27, 2022
The FAIR Data Innovations Hub Will Continue to Help the FAIRification of SPARC Data
 Bhavesh Patel@bvhpatel
Bhavesh Patel@bvhpatel
The FAIR Data Innovations Hub will continue the development of SODA, the software that makes it easier for researchers funded by the NIH SPARC program to make their data Findable, Accessible, Interoperable, and Reusable (FAIR).
The NIH SPARC program
The National Institutes of Health (NIH) launched the Stimulating Peripheral Activity to Relieve Conditions (SPARC) program in 2014. The program's goal is to accelerate the development of therapeutic devices, known as neuromodulation devices, that modulate electrical activity in nerves to improve organ function. Early research investigating such devices showed great promise for the treatment of diverse diseases and conditions such as hypertension, heart failure, and gastrointestinal disorders. The detailed underlying physiology and mechanisms of action of these neuromodulation therapies, however, are poorly understood in many cases. The SPARC program thus supports multidisciplinary teams of researchers to investigate the mechanisms of neuromodulation therapies in several organ systems (heart, lung, stomach, colon, etc.). The program also supports the development of novel electrode designs, minimally invasive surgical procedures, and stimulation protocols for new neuromodulation therapies.
Strict data curation and sharing guidelines
A major aim of the SPARC program is to maximize discoveries from data generated by SPARC-funded projects. To achieve that, strict data curation and sharing guidelines have been developed and are imposed to all SPARC-funded researchers. These guidelines align with the Findable, Accessible, Interoperable, Reusable (FAIR) data principles, which are widely adopted high-level guidelines for optimizing the reuse of data by humans and AI systems. The SPARC guidelines instruct researchers to follow a standard data and metadata structure, called the SPARC Data Structure when curating their dataset. Once the dataset is curated, researchers must upload it on the SPARC data platform Pennsieve, where additional metadata is required. After review by a team of curators, the dataset then becomes publicly accessible on sparc.science.
Data sharing challenges and birth of SODA
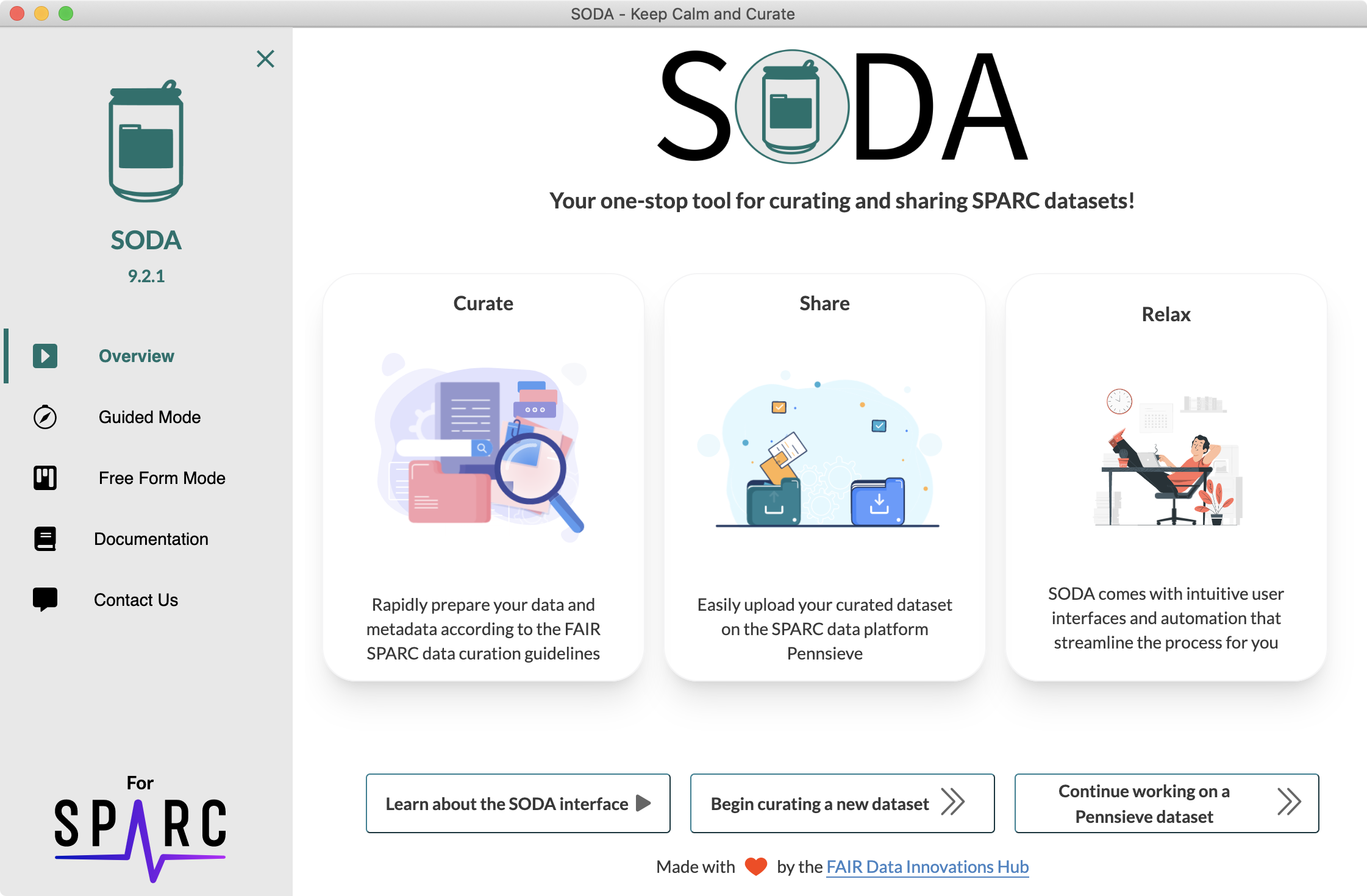
While supportive of this data-sharing initiative, SPARC-funded researchers expressed difficulties mainly due to a lack of time for learning and implementing these complex and extensive guidelines. I experienced these difficulties firsthand when I was put in charge of curating and sharing data from the SPARC awards received by the California Medical Innovations Institute. To address these difficulties, I had the idea of developing a tool that would guide me step-by-step into making my data compliant with the SPARC guidelines and would automatically perform tasks that could be accomplished by a computer, such as creating some of the metadata files. With a team of other SPARC researchers, we built a prototype of such a tool during the 2018 SPARC Hackathon where it received the People's Choice Award. Presenting to researchers a tool that will save them time and effort turned out to be a winning formula. While the winning prize at the Hackathon was only a “SPARC” branded mug, the NIH expressed great interest in funding further development of this software. This is how we started in May 2019 the development of SODA (Software to Organize Data Automatically), a cross-platform and open-source desktop software. The goal of SODA is to simplify data curation and sharing for SPARC researchers through a software that combines an intuitive user interface and automation. Various evaluations throughout the development have shown that SODA reduces researchers' time, complexity, and human errors in the SPARC data curation and sharing process.

Plans for the upcoming year
The SODA application is now in its fourth year of funding. During this Phase 4 (September 2022 - August 2023) of development, we will continue to implement additional features to further improve SODA. Specifically, we will:
- Adapt SODA's data organization and submission workflow to support non-SPARC datasets.
- Maintain up-to-date integration with the SPARC data validator.
- Continue to support the evolving SPARC metadata standards.
- Achieve continued integration with the SPARC data platform Pennsieve.
- Update SODA's usage tracking method.
- Provide an interface for connecting/disconnecting from platforms integrated with SODA.
- Promote the use of SODA.
Our long-term goal is to reduce as much as possible the time and effort required to curate and share data according to the SPARC guidelines. We believe that the rapid dissemination of well-curated SPARC data through SODA will continue to enhance SPARC's mission of accelerating the development of neuromodulation devices. As the SPARC guidelines are adopted outside of SPARC, we believe that SODA will similarly benefit these projects as well.
Funding and collaborators
This project is supported by the National Institutes of Health. The development of SODA was funded through a subaward to our SPARC research award during year 1 (3OT2OD025308, May 2019 - August 2020) before receiving a dedicated award from year 2 onward (OT2OD030213, September 2020 - Present).
We are excited!
The FAIR Data Innovations Hub is delighted to continue being a part of the NIH SPARC program, where it all started for us!